Automating a data science model involves creating a system that can automatically perform data processing, model training, and deployment without requiring constant human intervention. Here are some general steps you can take to automate your data science model:
- Train your data science model
- Host your model in a dedicated server
- Build an interface for your users to utilize the model
- Turn on the scheduler to feed live data
- Collect user feedback
Now, we will go through each step in detail to help you understand the process and use Acho as an example.
Step 1: Train your data science model
Preparing your model is the first step in automating a data science pipeline. This involves selecting the appropriate algorithms and data preprocessing techniques to optimize your model's performance. You should also select the appropriate evaluation metrics to ensure that your model is performing well and make sure that your data is of high quality and well-prepared for training.
Step 2: Host your model in a dedicated server
Once you have trained your model, the next step is to host it on a dedicated server. This server should be designed to handle the computational demands of your model and should have robust security measures in place to protect the integrity of your data. On Acho, you can import your Python project into a Python node.
Step 3: Build an interface for your users to utilize the model
To make your model accessible to users, you should build an interface that allows them to submit data and receive predictions. This interface should be user-friendly and provide clear instructions on using the model. (See a demo forecasting app below)
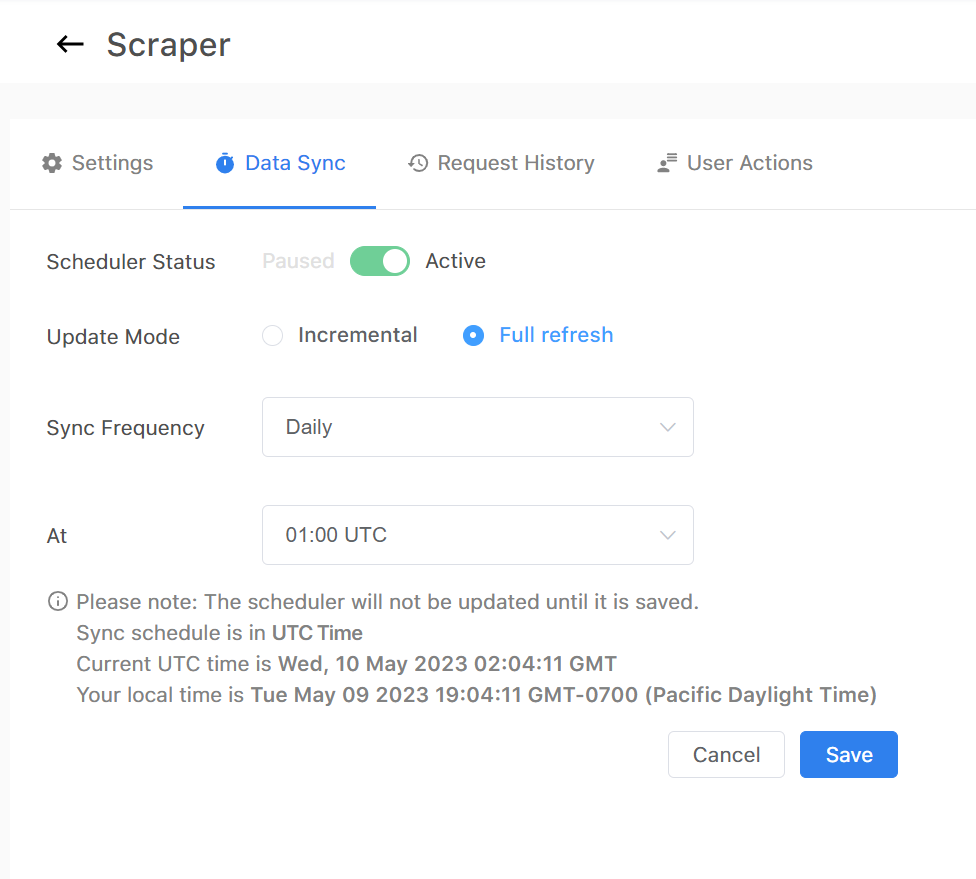
Step 4: Turn on the scheduler to feed live data
Once your model is hosted and the interface is built, you can set up a scheduler to feed live data into your model. The scheduler will automatically feed new data into your model at specified intervals, ensuring that your model is continuously updated and remains accurate.
Step 5: Collect user feedback
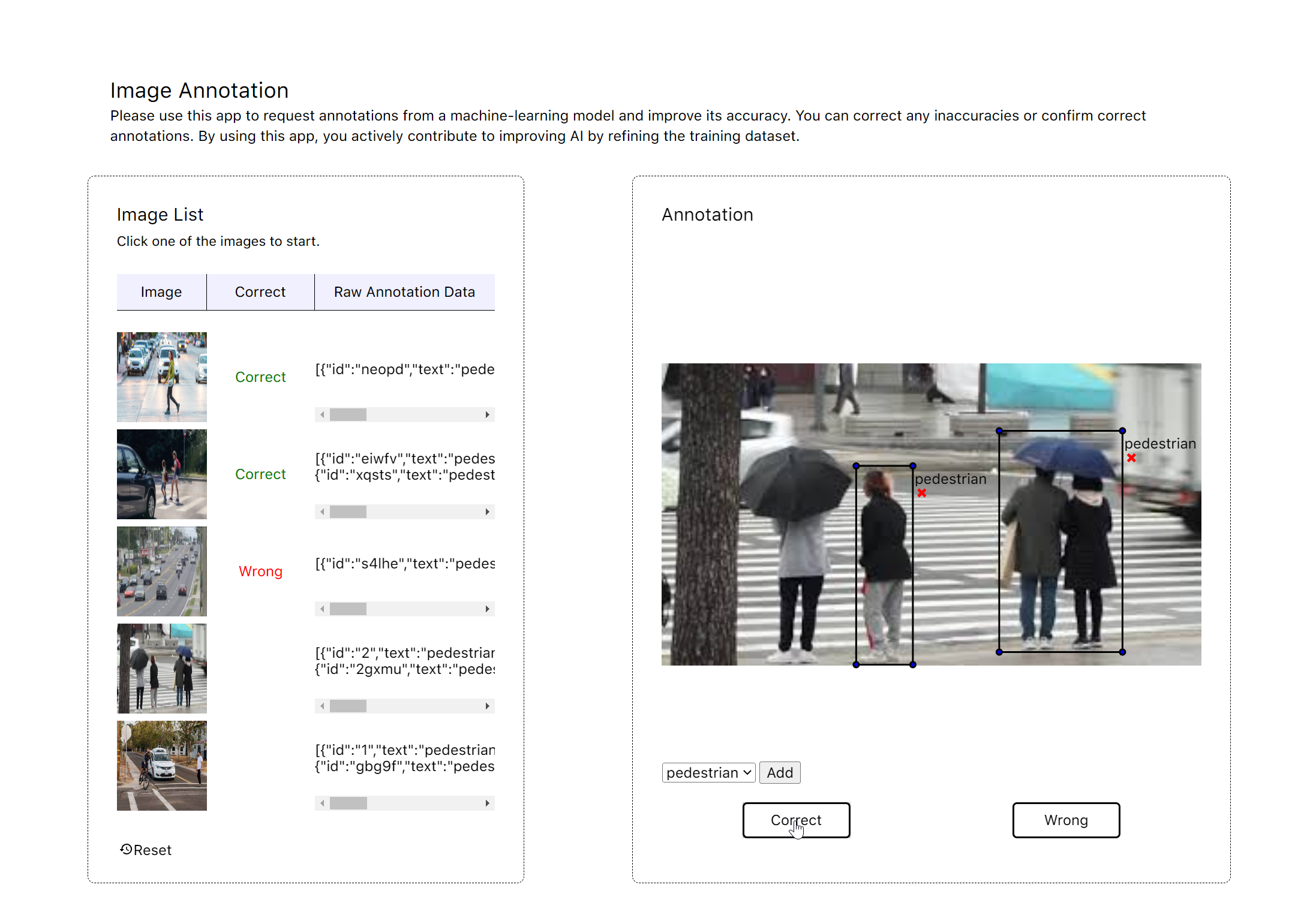
To improve your model's performance, you should collect user feedback on the predictions it makes. This feedback can identify areas where the model is making errors and refine its algorithms and parameters. There are two ways to collect feedback. First, you can record your user behavior in the backend and then use the data to improve your model. Another way is to allow users to report and correct it to the right answer. (See a demo image annotation app below here)
Step 6: Continue training
Finally, you should continue training your model on new data to improve its performance over time. This involves incorporating new data into your existing model and fine-tuning its algorithms and parameters to optimize its performance. You should also evaluate the performance of your model on a regular basis to ensure that it meets the needs of your users. Additional steps could include version control of your model, scaling and monitoring your infrastructure, and incorporating automatic retraining to improve your model continually.
If you’re interested in automating your data science pipeline, we are happy to help you learn more about it. Contact us in the chat box on the bottom right corner of this page if you have any questions!
- Schedule a Discovery Call
- Chat with Acho: Chat now
- Email us directly: contact@acho.io