What is a data pipeline?
In Acho Studio, all actions are applied in a sequence such as Filter → Join → Formula → Cleanse. Once you have defined your data workflow, each transformation can be dependent on the successful completion of the previous action. These transformations defined by your input parameters will be enforced by Acho’s Data Sync feature.
Differences between a data pipeline and spreadsheet
A spreadsheet is a grid of cells that record a value independently of other cells. This way you can enter any value, whether it be a date, integer or string in your spreadsheet cells. It is great for data entry and basic data modeling. For example, accountants use spreadsheets to keep a book of a company’s cash flow and build financial models for projections.
Unlike a spreadsheet, a database is an organized collection of data, typically stored in certain formats such as MySQL or MongoDB. It is built to record large amounts of data, update it regularly, and support analytics and applications.
To understand more about this, you can read this article called “The difference between spreadsheet and database”
A pipeline only applies to a database. It helps transform a database based on a predefined parameter such as filter, or a table join. It may also help transport data from one system to another based on the transformation. In most data pipelines, they consist of three key components: a data source, transformations (processing steps), and a destination.
Why do you need a data pipeline?
There are many reasons for why you need to build a data pipeline.
1. Store a large amount of data
Take a large data CSV file as an example, it would consume a great amount of computation power for a spreadsheet program such as Excel or Google Sheet to access. Imagine these spreadsheets programs needing to log every data point in every cell. This is when you may need a database program to store these records.
Transforming these data records on the other hand will need a data pipeline that has each step logically defined. For example, you have a file that contains 10 million records on all commercial buildings in the USA. You will need to segment these buildings by counties and load each segmented piece into a geographic information system. After loading this data in a database, you will need to
1. Sort the table based on zip codes
2. Apply filters on the zip codes to get relevant results
3. Combine the table with another table that contains the county name based on the zip code
4. Export the tables. These 4 steps are essentially a data pipeline.
If your file actually updates, this pipeline needs to be run each time when the original table updates so you will get the most relevant result table that also contains the updated data records.
Learn how to open a large spreadsheet or data file, check out this tutorial on “How to open big CSV files”.
2. Maintain a structured database
To keep a database regularly updated without breakage, and missing data, a rigorous pipeline needs to be built. The pipeline transforms a table based on a sequence of logical steps that will in the end produce a result table that fulfill business agenda.
When the business goal changes, this pipeline needs to be amended to reflect different data requirements. For example, you are building a trading application and you want to deliver unique insights to your customer based on publicly available information. You would therefore need to build a data pipeline that would produce these new data products without changing the original data source.
3. Unify data from different sources
Data is the most powerful when it’s connected from sources. Take a social media company as an example, they will receive a lot of user behaviors data from different products. To provide a holistic view for the advertisement bidders, they would need to unify all behavior data based on customers’ IDs. To enable ad bidders to compete for precious online spaces in real-time, these pipelines need to be run as fast as possible to reflect the gradual changes in user behaviors.
One these data sources are unified and connected, this holistic view for understanding user behavior becomes extremely valuable.
4. Support dashboards, automations or apps
An efficiently designed data pipeline can support an application or analytical dashboards in real-time. It will deliver actionable insights for users and decision makers with minimum delays.
How to build a data pipeline?
Now, how do you build a data pipeline? Traditionally, you will need to consult a technical person. He/she would help you extract data from a source, transform it based on your requirements and then load it into a destination you want. This is called an ETL (extract, transform, and load process).
Until recently, ETL was an industry standard for building a data pipeline. Lately however, a new process called ELT (extract, load, and transform) becomes more popular. This process would essentially load the data before transformation, and therefore helps a user transform the data within storage using the same computational resource that hosts the data. This way, it’s more customizable for transformations.
In short, you can build an ELT pipeline easily on Acho Studio. Simply connect your data source with Acho first, load it into a project, and then transform your data with built-in SQL actions. The transformations would eventually look at something like this.
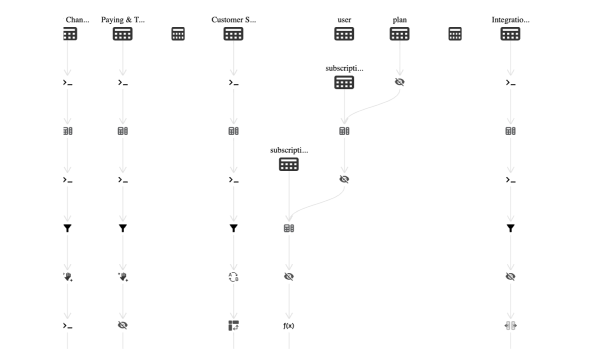
You can find a chart like this on your Acho Studio project’s Timeline. After defining these steps such as filter, hide column, and join table, you will have a rigorous data pipeline that will ensure your data updates