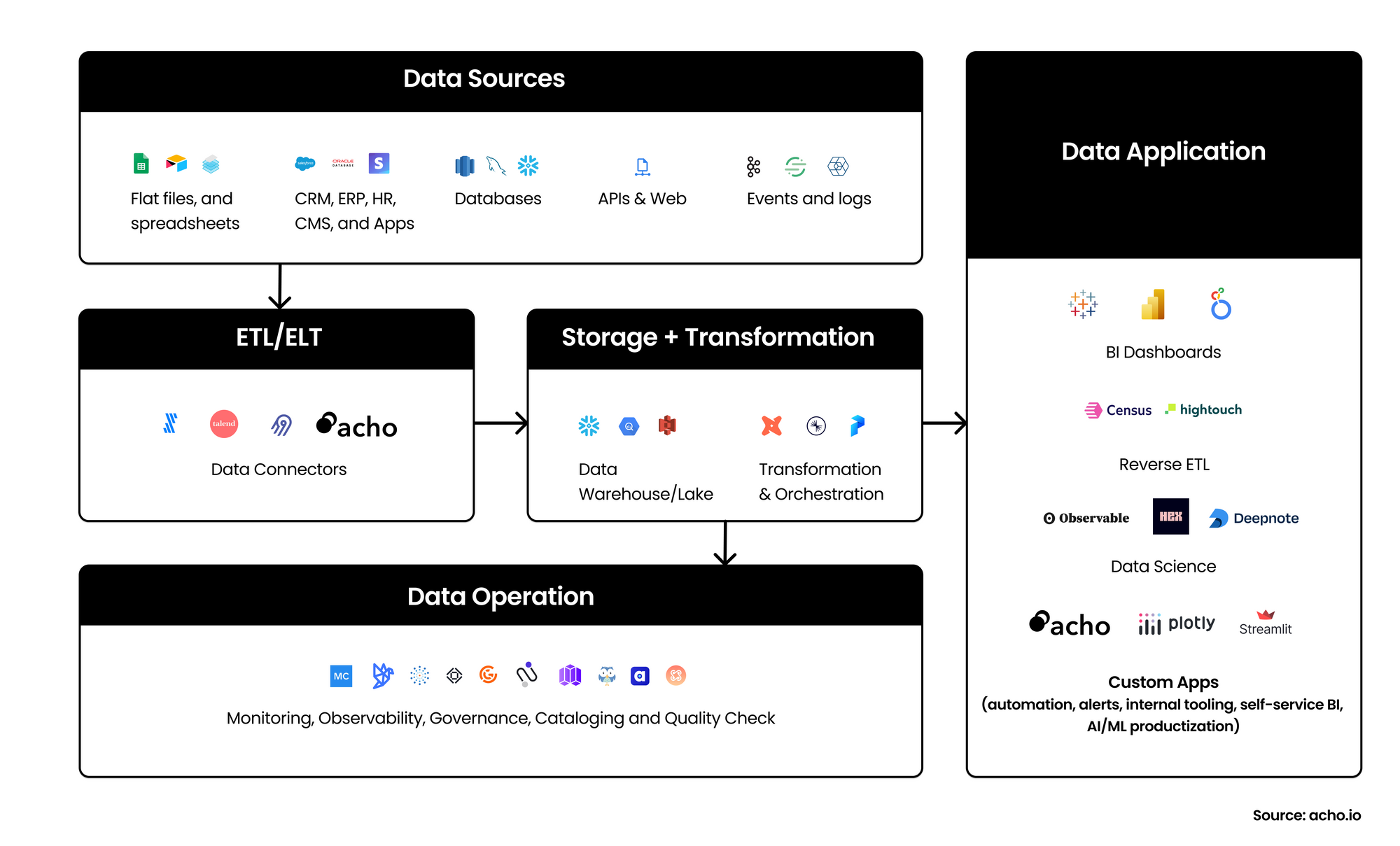
Building a modern data stack involves combining various tools and technologies to create an efficient, scalable, and reliable system for storing, processing, analyzing, and visualizing data. The key components of a modern data stack include data sources, data storage, data processing, and data visualization. Here are the steps to build a modern data stack:
- Identify data sources: Determine the sources of data that you will be working with. These could include databases, APIs, log files, cloud services, and third-party applications.
- Choose a data storage solution: Select a data storage solution that fits your specific use case, data volume, and data structure. Some popular options include:
- Data warehouses: Amazon Redshift, Google BigQuery, Snowflake
- Data lakes: Amazon S3, Google Cloud Storage, Azure Data Lake Storage, Databricks Delta Lake.
- Time-series databases: InfluxDB, TimescaleDB, OpenTSDB.
- NoSQL databases: MongoDB, Amazon DynamoDB, Google Cloud Firestore, Apache Cassandra.
3. Implement data integration tools: Choose data integration tools to ingest, clean, and transform data from various sources into your data storage solution. These tools should be able to handle batch and real-time data ingestion. Some popular data integration tools include:
- Apache Nifi, Apache Kafka, Apache Flink
- Acho, Stitch, Fivetran, Talend, Matillion
- AWS Glue, Azure Data Factory, Google Cloud Dataflow
4. Select a data processing and transformation tool: Pick a tool or framework to process, clean, and transform the data within your storage solution. Some popular data processing tools and frameworks include:
- SQL-based transformation tools: dbt (Data Build Tool), Apache Beam, Apache Hive
- Data processing frameworks: Apache Spark, Dask, Hadoop MapReduce
- Workflow management tools: Apache Airflow, Prefect, Luigi, Dagster
5. Choose a business intelligence or data application tool: Select a BI tool or data application tool to analyze, visualize, and share insights from your data. Some popular analytics and BI tools include:
- BI: Tableau, Power BI, Looker, Sisense, Google Data Studio, Amazon QuickSight, Domo, Metabase
- Data Application: Acho, Streamlit, Plotly Dash
6. Implement proper security measures: Ensure that your data stack is secure by implementing access controls, encryption, and data privacy best practices. This may include:
- Data encryption at rest and in transit
- Access control with role-based permissions and single sign-on (SSO)
- Data anonymization or pseudonymization to protect sensitive information
- Regular security audits and monitoring
7. Monitor and optimize your data stack: Continuously monitor your data stack's performance, usage, and costs to identify potential bottlenecks and optimize resource usage. Implement logging, metrics, and alerting systems to track your data stack's health and performance.
By following these steps and selecting the right tools and technologies for your specific needs, you can build a modern data stack that enables efficient data processing, analysis, and visualization, while ensuring scalability, reliability, and security.
| Component | Description | Examples |
|---|---|---|
| Data Ingestion | Collect and import data from various sources into a data storage system. | Apache Kafka, Apache Nifi, AWS Kinesis, Logstash, Fluentd, Stitch, Fivetran, Talend. |
| Data Storage | Store the ingested data in a scalable and reliable storage system. | Amazon S3, Google Cloud Storage, Azure Blob Storage, Hadoop HDFS, Snowflake, BigQuery, Redshift, PostgreSQL, MySQL. |
| Data Processing & Transformation | Clean, transform, and aggregate data to prepare it for analysis. | Apache Spark, Apache Flink, Apache Beam, Google Dataflow, AWS Glue, dbt, Dataform, Azure Data Factory. |
| Data Modeling | Organize and structure the data for analytical purposes. | Star schema, Snowflake schema, Data Vault, Anchor modeling. |
| Data Warehouse / Data Lake | Centralized storage and management of large volumes of structured and unstructured data. | Snowflake, BigQuery, Amazon Redshift, Azure Synapse Analytics, Databricks, Apache Hive, Delta Lake, Apache Hudi. |
| Data Analysis & Business Intelligence | Analyze and visualize data to generate insights and support decision-making. | Tableau, Power BI, Looker, Qlik, Domo, Mode Analytics, Metabase, Apache Superset. |
| Data Application | Productize data, provide services, and digitalize processes for teams. Examples include internal tools, automation, self-service BI, and AI/ML productization. | Acho, Streamlit, Plotly Dash |
| Data Governance & Security | Ensure data quality, consistency, privacy, and compliance with relevant regulations. | Apache Atlas, Collibra, Alation, Talend Data Catalog, AWS Lake Formation, Google Cloud Data Catalog, Azure Purview. |
| Data Orchestration & Workflow Management | Automate and manage data pipelines and workflows across the data stack. | Apache Airflow, Prefect, Luigi, AWS Step Functions, Google Cloud Composer, Azure Data Factory, Dagster. |
Contact us in the chat box on the bottom right corner of this page if you have any questions!
- Schedule a Discovery Call
- Chat with Acho: Chat now
- Email us directly: contact@acho.io