What is a data dictionary?
- History of a data dictionary
The idea of a data dictionary originates from the RDBMS providers back in the 80s. The term is interchangeable with “metadata repository”, and “metadata management”. Since the concept first came out, there have been many best practices promoted to help understand data assets better. Often a data dictionary is discussed in relation to data dictionaries such as “data glossary”, “data catalog”, and “data repository”.
- Types of data dictionaries
There are two types of data dictionaries. Active and passive data dictionaries differ in level of automatic synchronization.
Active Data Dictionary- A data dictionary that is automatically updated by the DBMS every time the database is accessed. This type of dictionary is primarily used by the DBMS software itself rather than the consumer of the data.
Passive Data Dictionary- It is not automatically updated and usually requires a batch process to be run.
Passive data dictionary systems are mainly used for documentation and require extra
operation to register meta-data, whereas active data dictionary systems are more powerful in implementing control mechanisms but all transactions must go through the system.
What does a data dictionary do?
For a well-built data dictionary, it should help users:
- Discover what data are available
- Where the data are located
- Understand the data attributes
- How the data are used (definitions of data security requirements: who is allowed to access the data, who is allowed to update/amend them)
- Relationships to other pieces of data or data interoperability
- Definitions of data integrity requirements
- Enforce data integrity policies by sanitation check
Why would you need a data dictionary?
- Make data assets visible
If you have a lot of data from different systems, it’d be difficult to locate each table within a reasonable amount of time. Typically these data tables can only be accessed and queried through SQL. This of course would require a good understanding of where the tables come from, their schema, and relationship between one from another. If you’re a database administrator, this perhaps wouldn’t be a big issue. However, if you’re a data consumer such as an analyst or business manager, it’d be a lot harder without prior knowledge of where the tables come from and how they’re designed.
Having a data dictionary is particularly useful to data consumers who want to explore a company’s data assets and try to find answers. A good data dictionary should be well-documented and searchable through natural language. For example, a simple search via a query string such as “billing status” or “backorder” should take you to the corresponding table and provide all necessary information about it.
- Avoid data inconsistencies
Data inconsistency means that different versions of the same data appear in different places. For example, a phone number column is saved in one table as 000-000-0000 while in another table it may be represented in 0000000000.
Another example is having duplicated data such as this table.
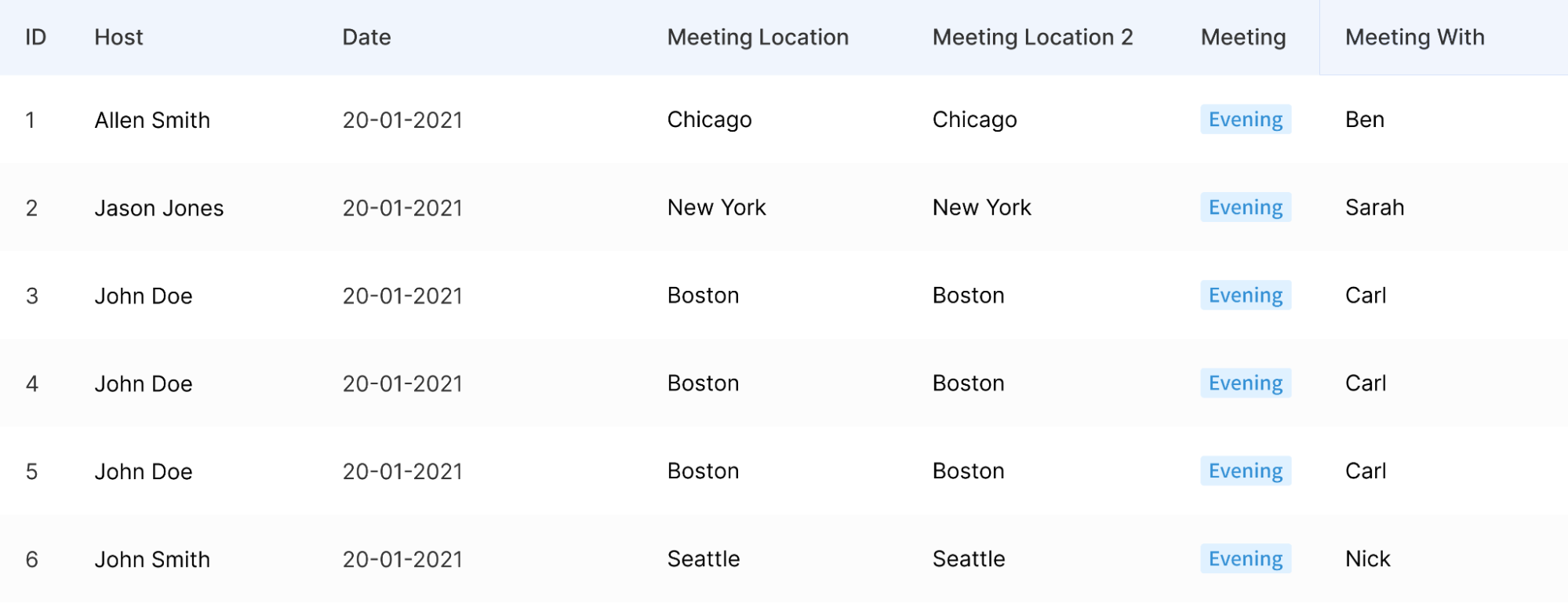
The duplicated columns and rows cause inefficiencies also known as data redundancy. A good data dictionary may help you locate these tables by retrieving their column name and even their row value. For example, you can find this table by searching “Meeting Location” or “John Doe” for duplicates.
- Optimize for resource allocation
Imagine having hundreds of your tables running on cloud while they cost thousands every month on hosting and updates. Many of these tables might be under-utilized or under-maintained. A well-documented data dictionary can help users find these tables quickly, monitor for updates, archive the unused tables if necessary.
- Transfer knowledge between data workers
When a database is viewed by another data consumer, it’d be hard for him/her to understand what the data entails unless properly documented. A data dictionary would help a lot when it comes to interpreting, and analyzing the data.
What are some of the current solutions?
- Spreadsheets
A spreadsheet program is perhaps the most popular way of storing data. Close to a billion users everyday use it for creating and collaborating with data tables.
Creating a data dictionary for a database can be as easy as extracting a list of columns using a query and pasting the results into a spreadsheet. However, the maintenance can be very laborious and time consuming - making sure it's up to date to the source often requires manual labor and sometimes straight-up impossible if the data scales fast.
- DB GUI
Another popular approach is to utilize a DBMS’s built-in data dictionaries. Most database engines (DBMS) have an so-called active data dictionary - an inventory of their data structures.
Most DBMSs also offer the capability to annotate data dictionary elements (called comments, descriptions or extended properties). Some teams choose to store their metadata in such a structure. Comments can be edited with many database management tools that are available for all databases. Then such a data dictionary can be shared with a database documentation generator that generates HTML, PDF or another format for easy access. This can be a feature built into a database GUI or a standalone tool.
To sum up, the advantages for using a DB GUI as a data dictionary include robustness and performance The disadvantage include high learning curve, inconsistent standards across platforms, and inadequacy in use cases that require historical records
- Internal Data Wiki
An Internal Data Wiki typically sits on top of a data warehouse and it encompasses all of the working data tables while providing metadata for each of them. This knowledge layer of data documentation may serve as a feature to a data warehouse.
Compared to a spreadsheet, a data wiki feature helps locate tables dynamically. Most changes to the database can be reflected in the knowledge layer without additional copying and pasting. Compared to DB GUI, the data wiki can support data from different sources. For example, a simple text query “phone number” may produce results from multiple databases such as MySQL, MongoDB, or other.
How to create a data dictionary in minutes?
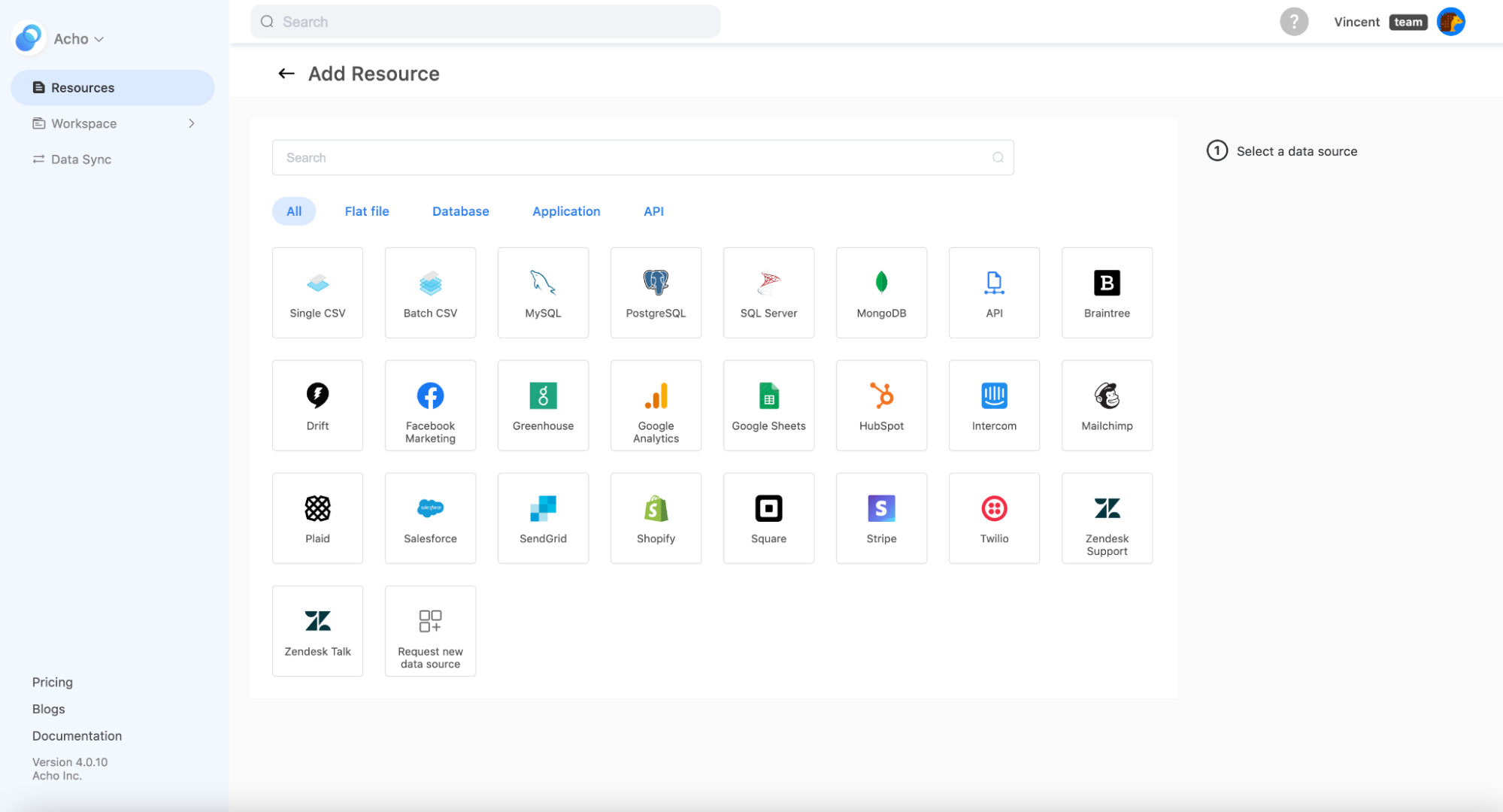
1. Connect data sources
Acho is an internal data wiki that can support queries across different data sources. To create a dictionary, you can first set up a connection between your data source and Acho.
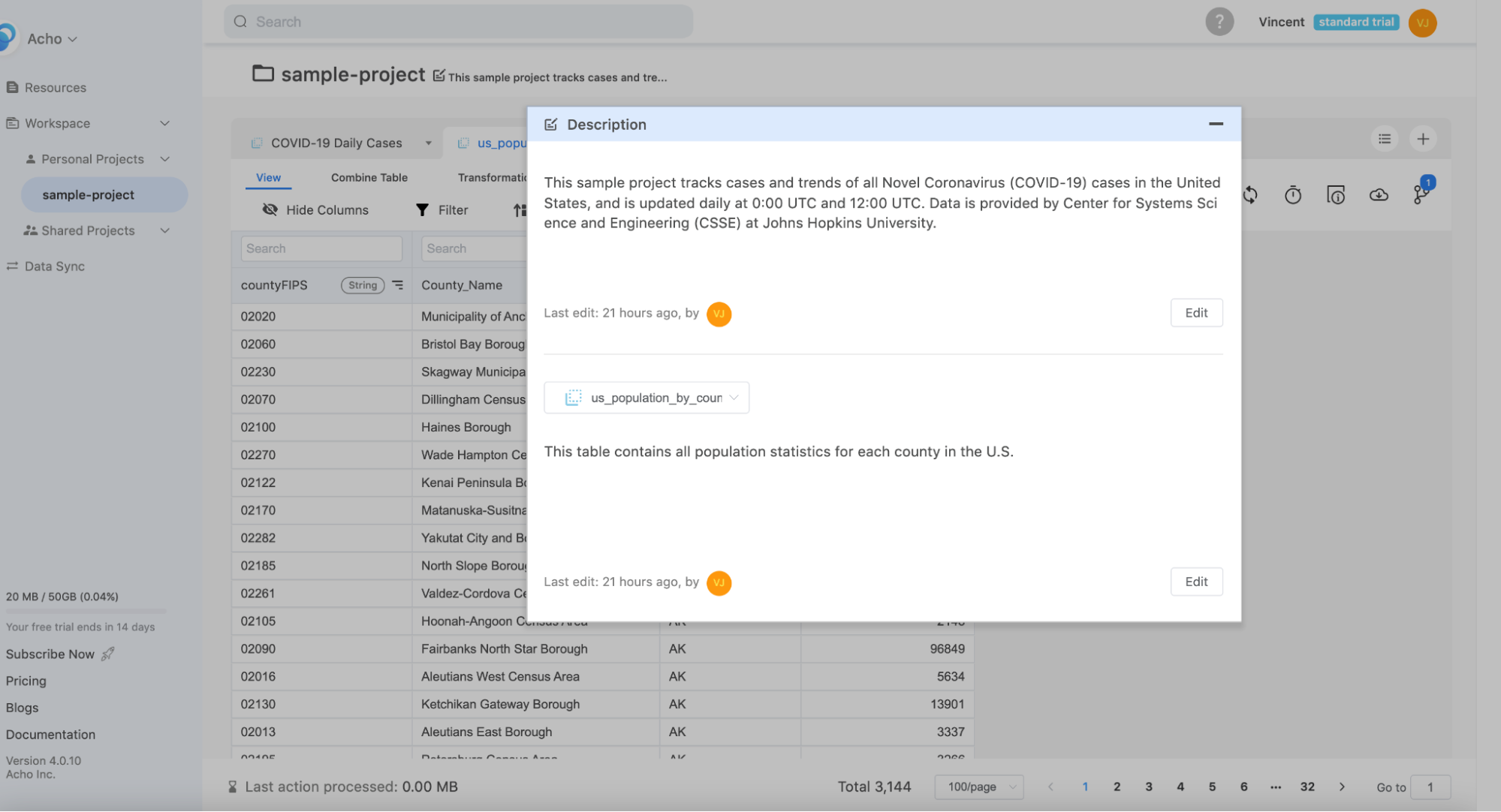
2. Document your data
Once a connection has been completed, you can produce metadata for each table. There are many places where you can document the data assets. Right after your resource, projects and tables have been created, they will be immediately searchable. Next, you can create a project to explore, and transform this resource. The project name, and the tables within it are also available to search.
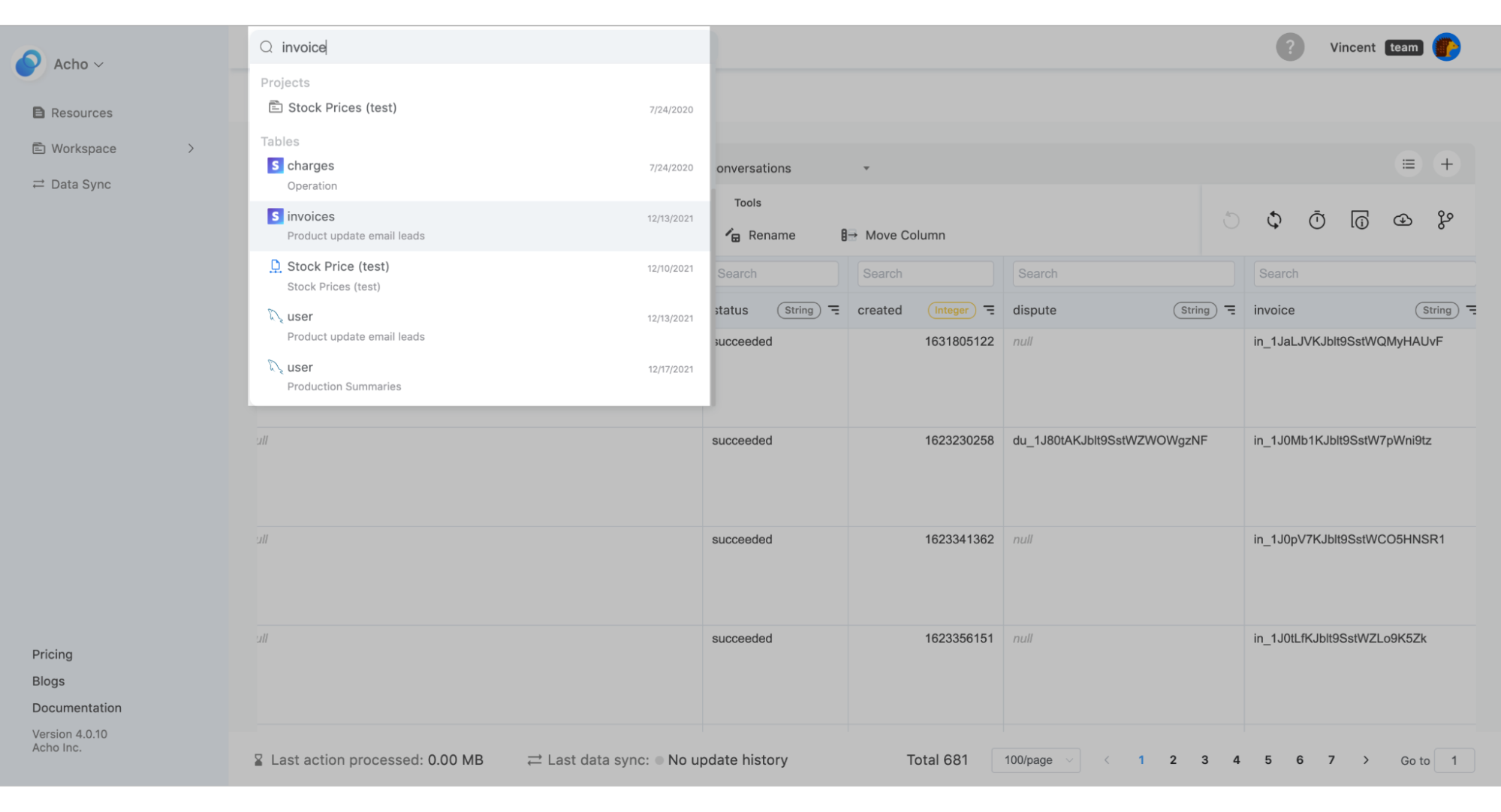
3. Search across data tables
Once your tables and projects have been properly documented, you can search across all of these assets instantly. By inserting a term inside of the search bar, you can find corresponding resources, projects, and tables instantly.
4. Invite your teammates
Once your tables and projects have been properly documented, you can search across all of these assets instantly. By inserting a term inside of the search bar, you can find corresponding resources, projects, and tables instantly.
Reference: