Between accounting software, project management tools, all the many advertising platforms, CRMs, and other various software, businesses nowadays have a lot of applications to juggle. Each one of these apps carry an abundance of data and it’s common to want to transfer data between 2 or more apps on a regular basis.
Data can be transferred between two applications to get better leverage out of the data. For example, if you’re using two CRMs, like Salesforce and HubSpot, you’ll likely want to transfer data between the two on a regular basis to make sure your customer data is up to date. Or if you have purchase order data in one application, you might want to incorporate it into HubSpot to better understand customer behavior.
There are many ways to transfer data, each with its own set of advantages and disadvantages. In this article, we’ll cover two of the most common ways of data transfer: API payloads and reverse ETL.
Through API payloads (for developers)
One common way to share data is through APIs. An API (Application Programming Interface) is a software-to-software interface that provides a secure and standardized way for applications to work and communicate with each other. They can be used to both get data from or send data to a service.
When sharing data between applications, the apps act as the endpoints while their APIs act as the intermediates, streamlining the data-sharing process. In the most simple terms, we can use API #1 to retrieve data from the origin app, then use API #2 to send that data to the destination app.
Reading documentation
The first step in this process is to understand each app’s API by reading its documentation. Not every software integration works the same way, so not all APIs are the same. The documentation helps developers understand how a particular API is used. For example, they’ll need to find the appropriate endpoint, required fields, and structure of the data.
The documentation will also describe how to code an API call. An API call is the process of a client application submitting a request to an API. There are four request methods it can take:
- GET: Retrieve a resource
- POST: Create a new resource
- PUT: Edit or update an existing resource
- DELETE: Delete a resource
To share data, we’ll be able to use the GET method to retrieve data, then use the POST method to send that data. In other words, we want to take the GET output of the origin app and input it into the POST payload to the destination app.
Finding common ground
Next, you’ll need to find commonalities and identify differences between the output and the input. What’s the format of the data retrieved by GET? Sending data with POST requires a request body, usually a JSON or array containing the values you want to create. What’s the required format of the request body?
For example, this POST method from HubSpot CRM API creates a batch of contacts. Under parameters, we see that the request body takes in an array of objects, each object being one contact and containing a deterministic set of information.
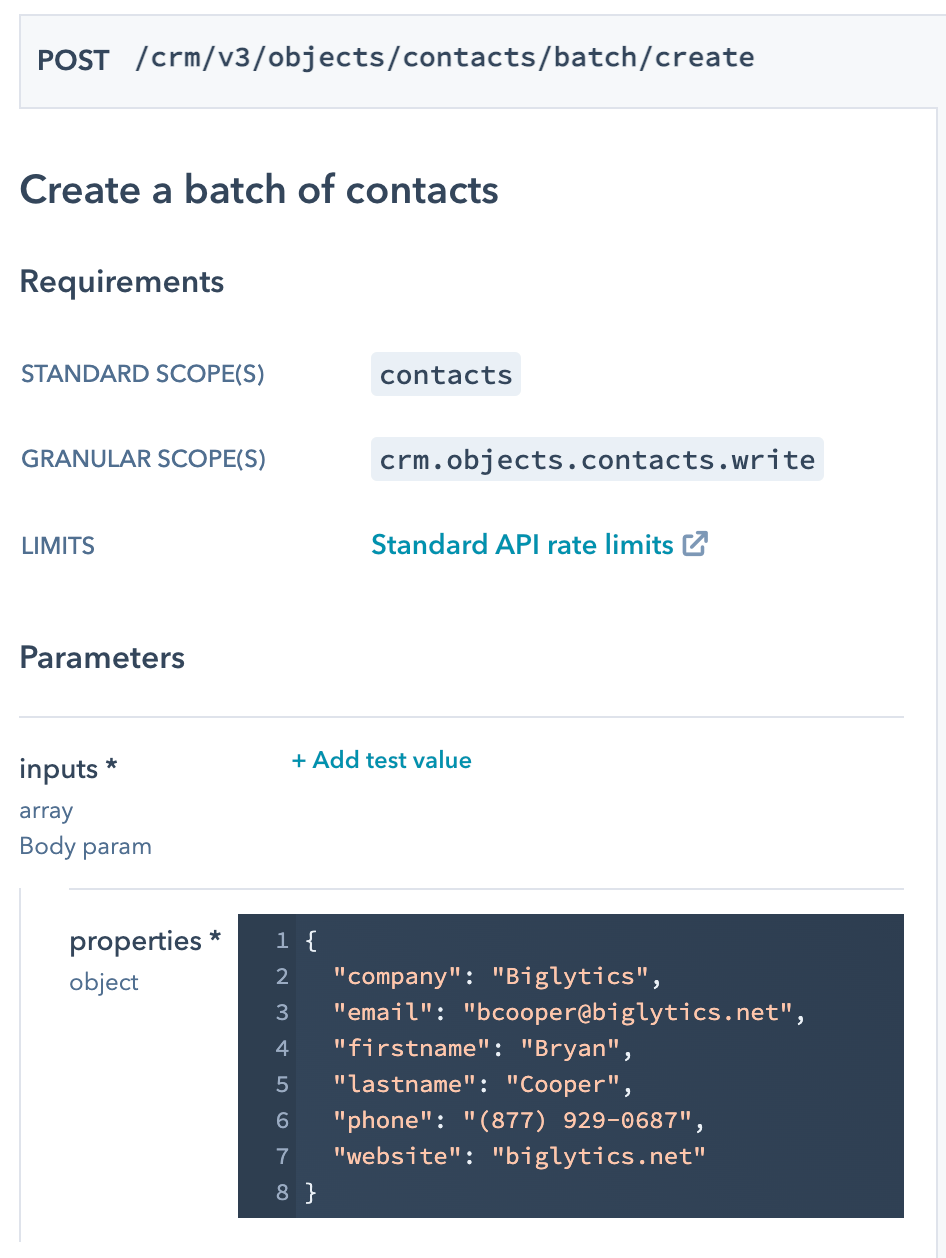
If there are discrepancies between the output and input, the data will need to be transformed before it’s put into the POST payload. Let’s say we’re trying to retrieve contact information from another app to import into HubSpot, but that app stores the contact’s first and last name as a single field. In this case, the first and last names will need to be separated to comply with HubSpot’s POST payload.
Writing script and testing
Up until this point, we’ve been examining the API and its documentation. Now we need to actually write the script to retrieve, transform, and send off the data.
Some APIs have better support for some languages, but in general, developers can use almost any modern programming language they’re comfortable with (like Java, Ruby, or Python) to interact with the APIs. Most languages are already sufficient for interacting with APIs, but developers usually also install additional packages for convenience.
Write your script based on the information gathered in the documentation for how to use the GET and POST methods and the framework for your chosen language. In your script, the data output should also be manipulated to format it for input.
When the script is ready, test it to validate the correctness in responses and data. Most API's are one-way, meaning a request is met with a response. The server will return a response code to indicate the status of the request. A successful request will have a response status code of 200. Any other code may indicate a server-side or client-side error.
Setting up a server
Each app’s data is stored in its respective servers and making API calls allows us to interact with those servers. But there still needs to be a way to host the job. When we pull the data to transform it, where does it go? You’ll need a server to host, maintain, and support your script.
With a reverse ETL pipeline (no-code)
Another method to share data is with a reverse ETL pipeline. Reverse ETL is the process of moving data from a data warehouse into third-party applications, such as CRM or marketing automation software. Data from one app can be pulled into a data warehouse and then sent off to another app.
Teams used to have to write their own API connectors to pipe data from their warehouse to a third-party app. They would face challenges dealing with brittle endpoints, mapping fields from the warehouse to the app, and maintaining the connectors over time as API specs change. It can also be difficult for some APIs to process real-time data transfer.
Reverse ETL tools help address those challenges by offering pre-built connectors, so teams no longer need to write and maintain custom solutions.
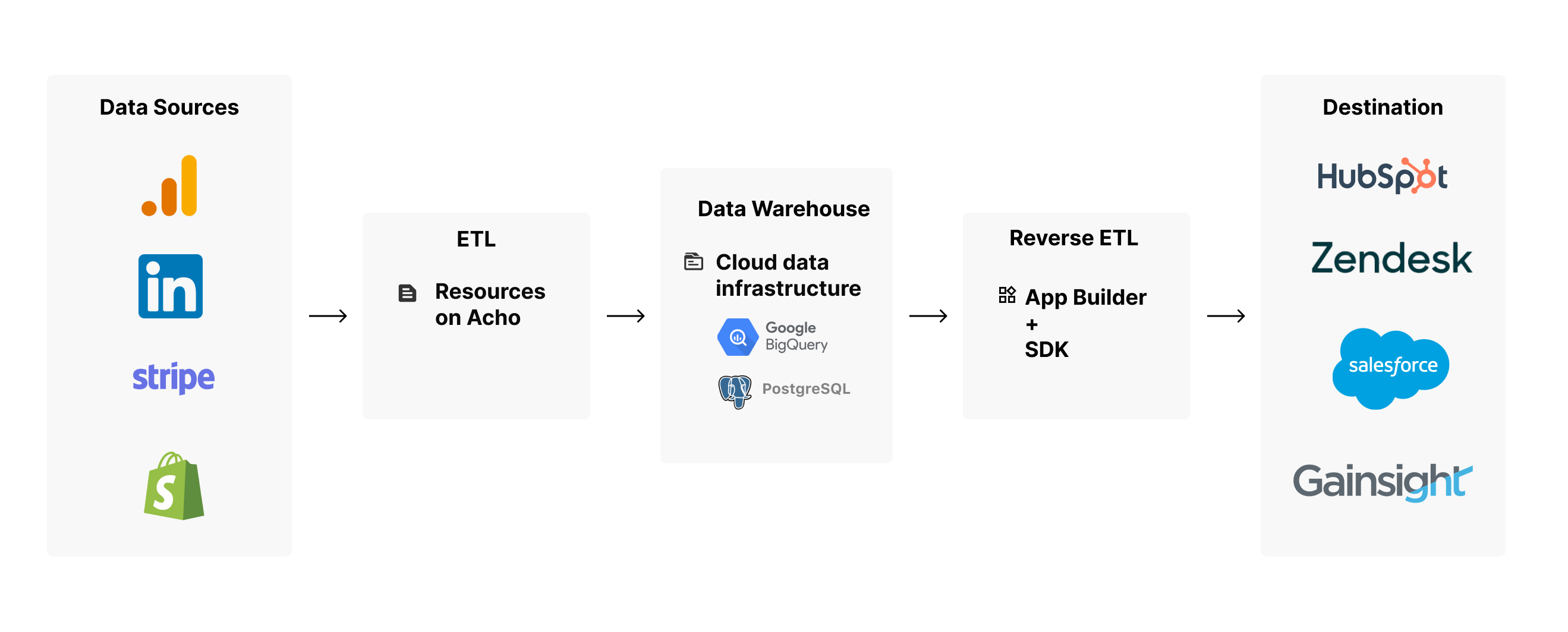
Store data from the origin app in a database
In order for reverse ETL to take data from a warehouse to an app, you’ll first need to load your data from the origin app into the warehouse. Data can be loaded by leveraging the app’s API or by using an ETL tool.
In the past, organizations built their own ETL workflow by writing scripts to manually retrieve data with an API call, transform it, and then load it into their data warehouse. However, this method requires technical understanding and maintenance as the API may change. Hand-coded data extraction can also be time-intensive and prone to errors.
Nowadays, there are many ETL tools on the market that can automate your data flow. These tools create a level of abstraction between the user and the technical details of ETL, often in a no-code or low-code interface.
Map data to the destination app’s table schema
Reverse ETL tools can take the loaded data and send it off to the destination. They come with mapping capability to define where the data from the warehouse source will fit into the destination app.
Before data is sent off to the destination app, the data should be transformed to easily map to the destination app’s table schema. The warehouse columns should correspond to the app’s schema.
Send data to the destination
Once a warehouse source is selected, an app destination is chosen, and the appropriate fields are mapped, the reverse ETL tool will send the data to the destination.
Check to see if the data has been successfully received at the destination app.
Set up a scheduler and monitor the pipeline
If the connection is successfully created, you can set up a scheduler to sync records automatically. You’ll be able to update your data hourly, daily, weekly, and even in real-time.
With automatic syncs, it’s essential to monitor the pipeline in case of breakage. Since apps and tools are constantly being updated and improved, the pipeline may need to be re-configured when changes are made. For example, if an app’s table schema changes, the sync may fail until the column mapping is updated. Stay aware of logs and alerts sent out by the system.
Tradeoffs for reverse ETL and API scripts
Real-time vs batch jobs
When developers build communication between two apps, real-time data transfer is typically imperative. Since most of these data transfers are small and have granular actions such as a “button click”, “page route”, or “file download”, the connection is optimized for speed and responsiveness. However, this is not optimal for a larger amount of data. Transferring a huge dataset between two apps through API can be slow and unstable.
Therefore, batch jobs are used for larger data transfers. In a reverse ETL pipeline, batch jobs are sourced from a database/warehouse and turned into events for a destination application to interpret. This (batch jobs) of course would not be ideal for instant communication between two apps. However, this kind of pipeline still has its value in terms of connectivity and automation.
No code needed
Another tradeoff for writing API scripts for app connection is the fact you’ll have to read a lot of documentation and write a lot of codes. Of course, it all depends on the complexity of the API data. Often, this is the most expensive part of setting up a connection between two apps.
On the other hand, setting up a reverse ETL pipeline is a very different practice since pre-built connectors are built for both data sources and destinations. The main job here is really to map the data fields. This can be a lot easier since you’re dealing with relational data in a tabular format. In another word, this is very similar to doing data cleaning/mapping on a spreadsheet. Typically, you wouldn’t need to write any code, though complex data mapping may still require writing SQL queries to achieve.
Hosting, monitoring, and observability
This sometimes can be a dealbreaker for a lot of teams. When writing API services, a server is required to host, maintain and support them. After the API services are written and put into production, additional services may be needed to monitor and observe the API data services. In other words, additional technical resources may need to be invested to ensure the deliverability, robustness, and performance of the API services.
In a reserve ETL pipeline, however, the data pipeline is typically fully managed in a third-party server or built within an existing database/warehouse. This of course can be much easier to configure, host, and deploy. Since the pipelines are hosted in an existing infrastructure, monitoring and observability can be a lot easier as well.
Data exploration
For a developer, reading API documentation for both data source and destination is considered “data exploration”. Experiences and good reading habits may help a lot.
For a non-developer, exploring data requires a good interface such as a column-based table or response console such as one offered in a Python notebook. Having a good interface means that opportunities for connecting the two apps and sharing data can be identified and established on the go without the extensive preparation needed for understanding the API documentation.
In summary, both methods for sharing data between apps can be described in the following table based on some of the aforementioned tradeoffs.
Contact us in the chat box on the bottom right corner of this page if you have any questions!
- Schedule a Discovery Call
- Chat with Acho: Chat now
- Email us directly: contact@acho.io