If you are dealing with a lot of large .CSV files, and you want to split them into small files, there are typically two things that you can do,
- Using Python or any server-side programming language (e.g. Terminal, Windows cmd, Java) to split the files
- Build a database and insert the .CSV files into it splitting them via a script/query
The problem with solution one is that running processes on GBs of data will put a lot of stress to your local computer. You also need to be very technical in order to handle different edge cases with your file.
The problem with solution two is that you’ll have to design a table schema and find a server to host the database. Also you need to write server side code to maintain or change the database.
There’s however another way to do this; upload your file to the cloud and have the cloud database handling your files. A number of advantages with this solution are 1. This way you won’t lose your original file saved on local. 2. No need to build a database on your own since it’s already built on the cloud. 3. It will be much faster processing your files on the cloud than locally.
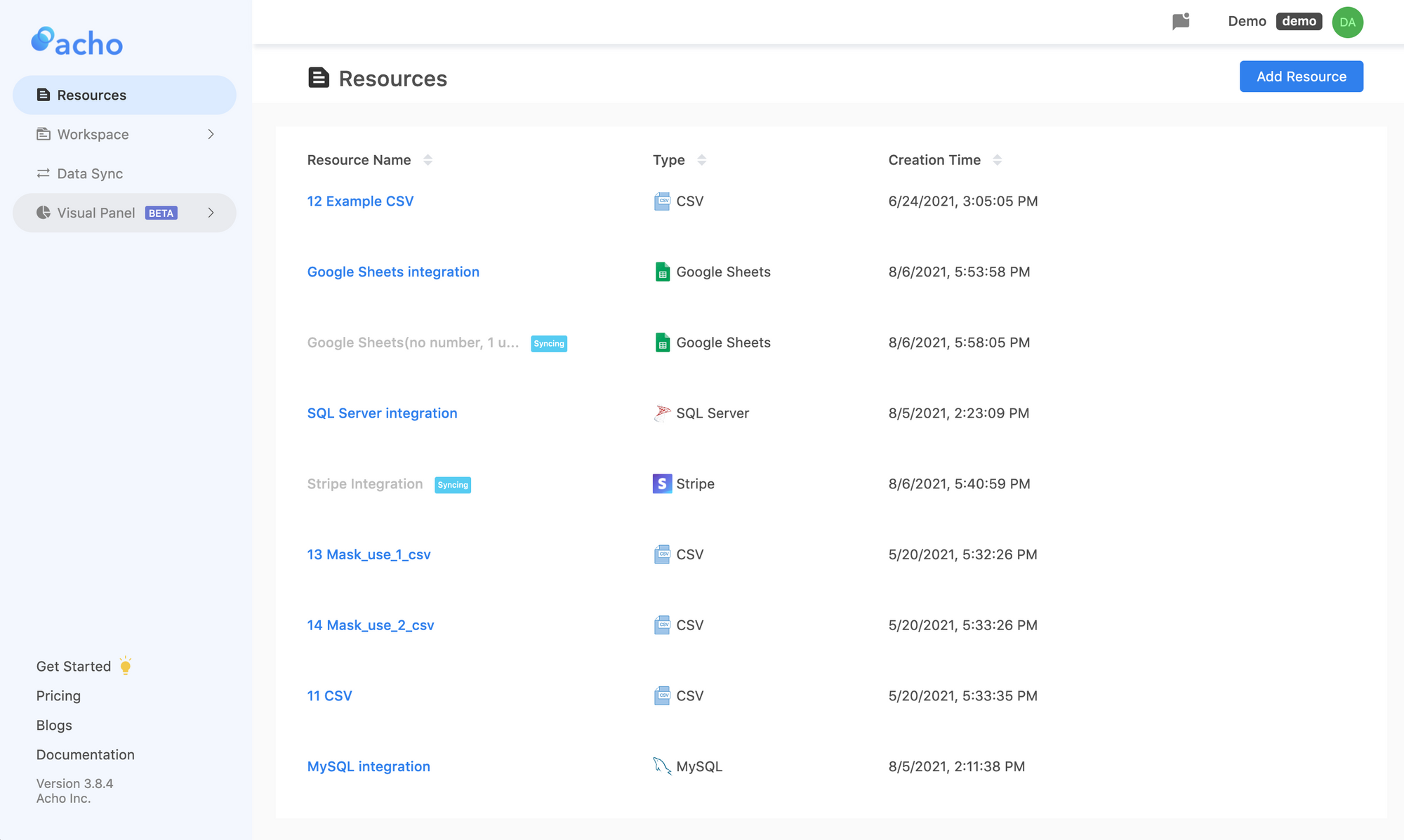
1. First, upload your .CSV file to a cloud database
By uploading your .CSV file to a cloud database, you’ve essentially turned your local .CSV file file into a database.
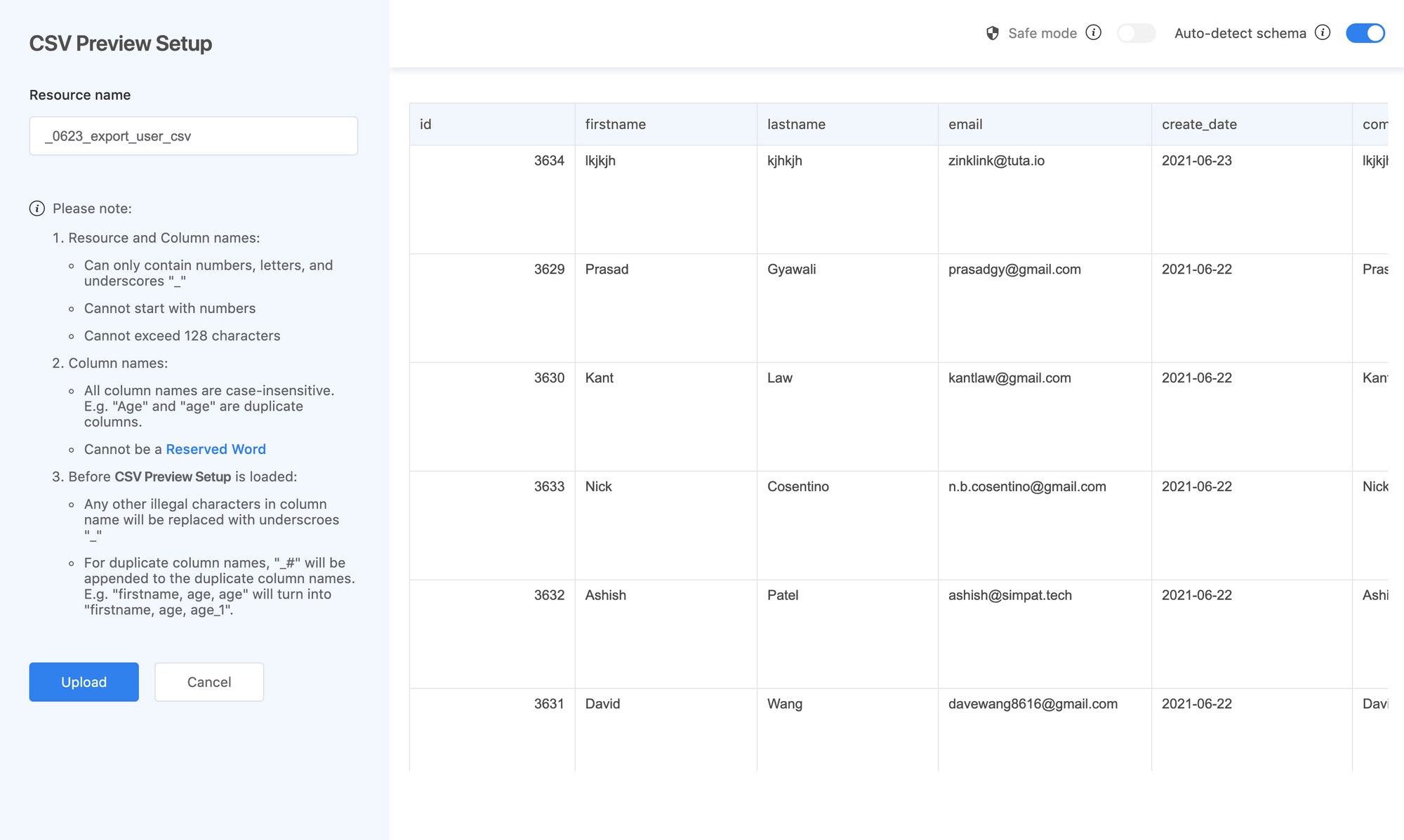
2. The built-in parser will handle your data
Most .CSV files are not perfect for databases . There could be 1. Missing values for valid columns 2. Invalid column names (special characters) 3. Too many columns (most databases support up to 10,000 columns 4. Corrupt values 5. Mismatched value type between the column and values. Most of these problems are handled in Acho Studio. You can use the built-in parser to make sure that your .CSV files are correctly inserted in a cloud database.
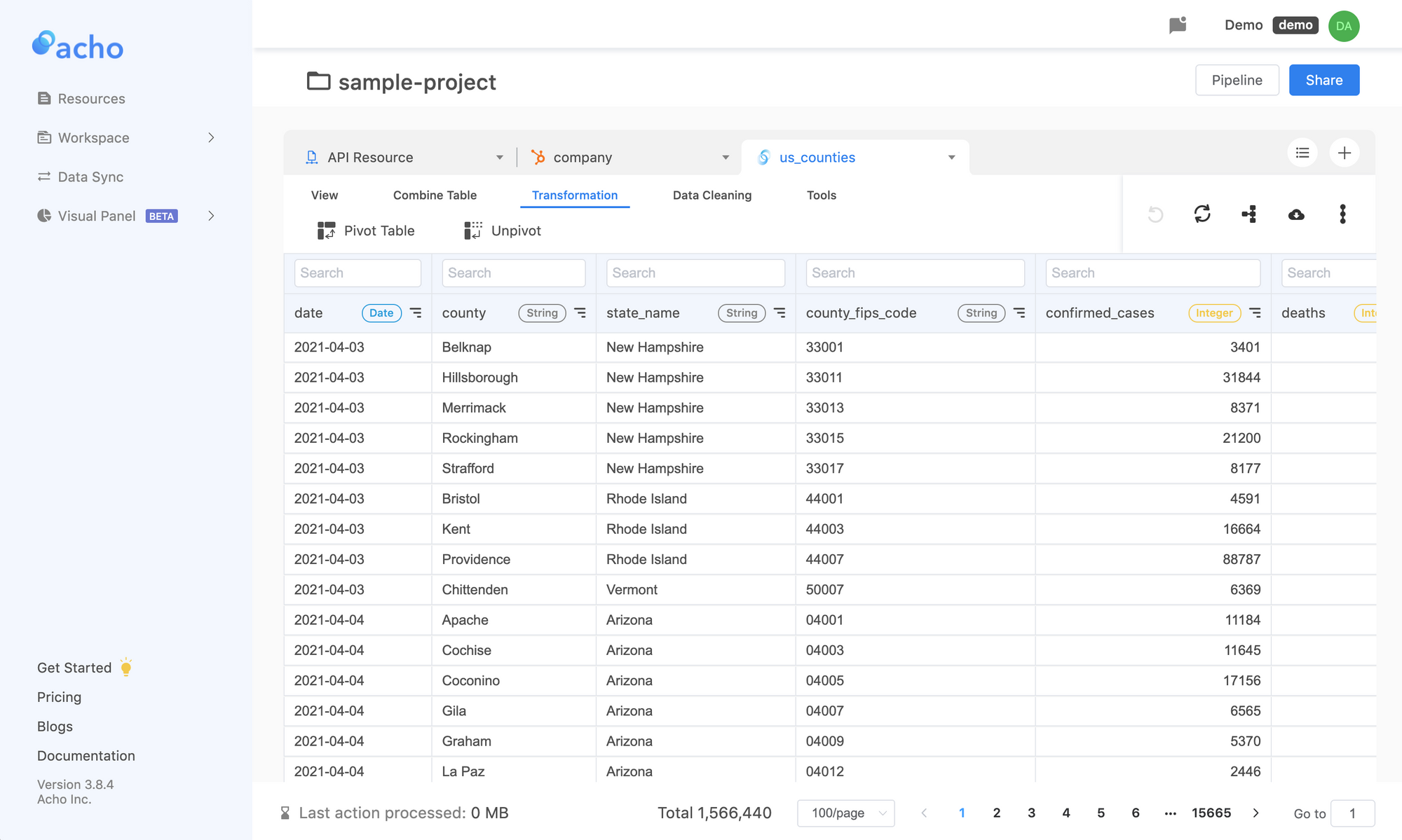
3. Load your table
Once your table is successfully loaded, you can start transforming the table to the format you want. Since this table is on a cloud RDBMS, you will not lose the original file every time that you transform it. Things you can do include “Filter”, “ Join/Merge”, “Find & Replace”, “Formula”, “SQL” and etc. These unique actions will help you prepare the final table before splitting it.
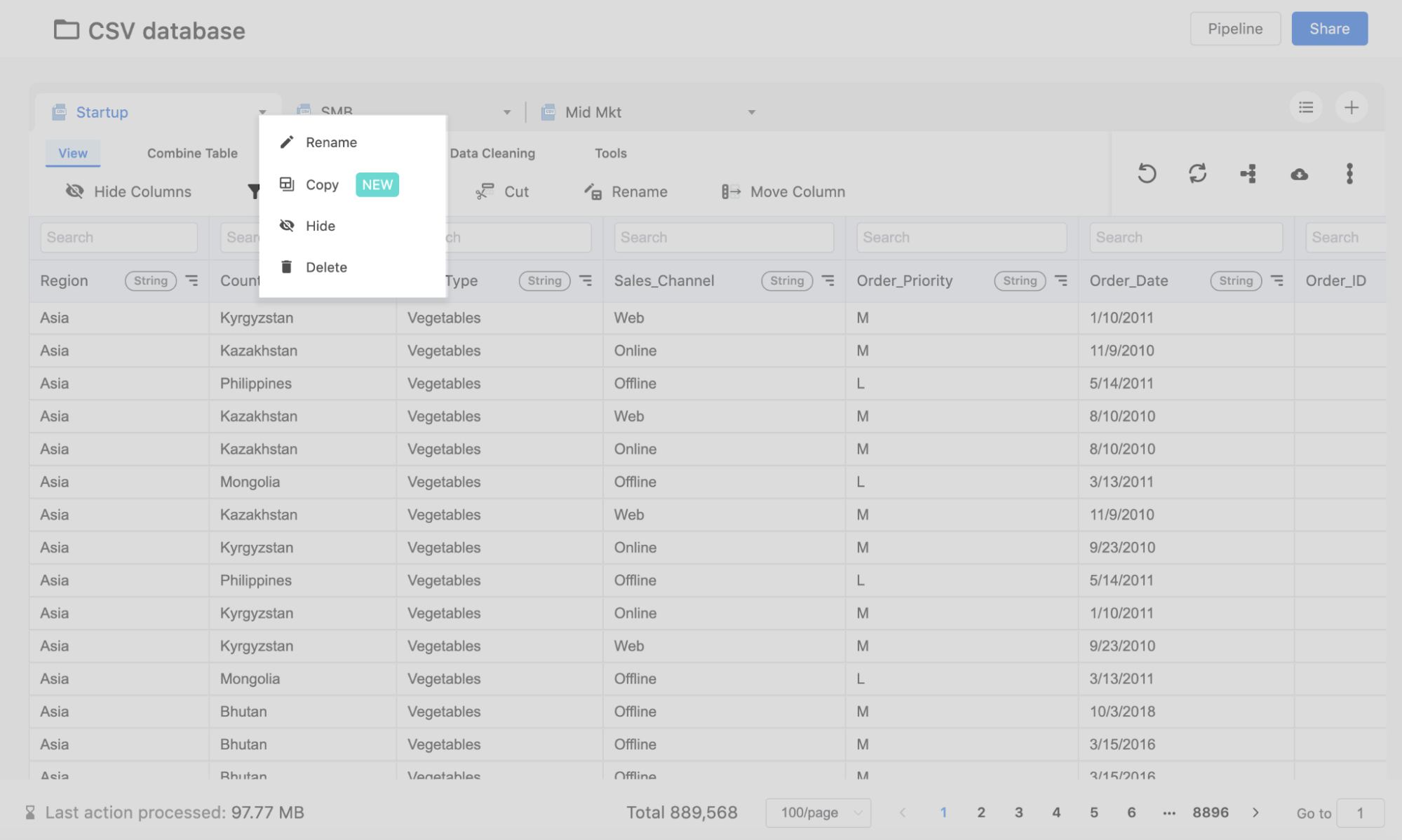
4. Filter & Copy to another table
One powerful way to split your file is by using the “filter” feature. It comes with logical expressions that can be applied to each column. Based on each column’s type, you can apply filters such as “contains”, “equals to”, “before”, “later than” etc.
Once you have filtered the result table you want, you can use the “copy” feature to save this table to another table. Here I have applied a filter for a certain product type. Then I can use the “copy” feature to replicate this table to another tab.
Now, you can go back to the original table by resetting the filter. Each version of your table after an action is recorded in the pipeline and you can freely go back and forth.
This way, you can copy each version of your table to a new tab without changing the original table.
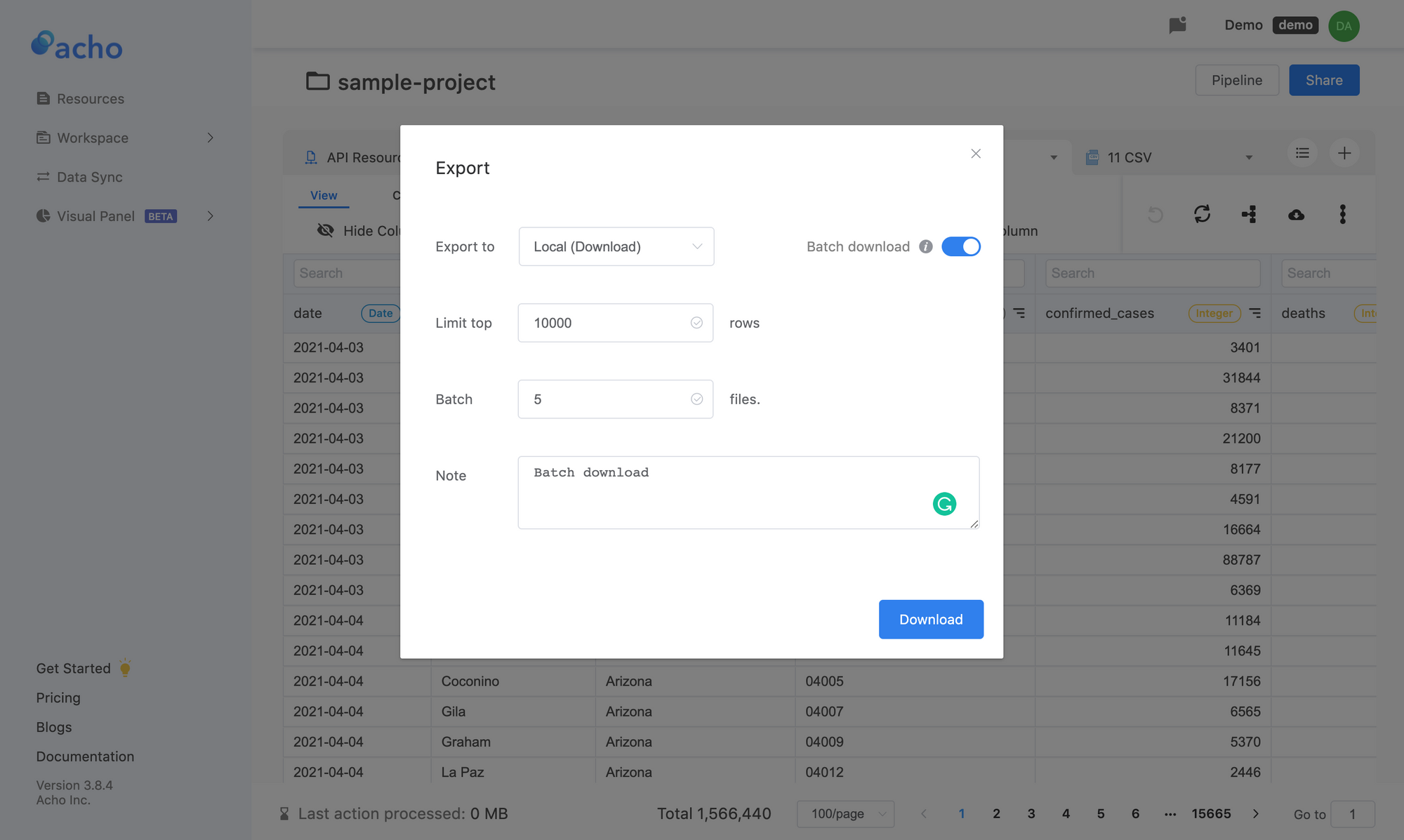
5. Download your data in batches
The last step of course is to download your finalized table in batches.
a. Click on the little cloud button on the top right.
b. Check the “Batch download” option.
c. Then you can select the rows and batches.
d. The downloaded file will be a .zip file that contains all your .CSV files.
For more details on how to split a CSV into multiple files, check out the following video tutorial.