One of the techniques of organizing data is database normalization where it is often used to reduce redundancy within relational databases, it is also used to rid of undesirable characteristics like Insertion, Update, and Deletion Anomalies. Normalization often will divide a large table into smaller tables and link them with relationships. This ensures that the data is being stored in a logical and concise manner.
Why do we need normalization?
Now with the brief introduction to the topic of database normalization, you may ask why do we need normalization and why is it important? As we mentioned before, data normalization helps rid of anomalies that may slow down and negatively impact the analysis of the dataset, therefore a well-functioning and organized database needs to undergo normalization to be successfully analyzed for data insights.
The importance of data normalization goes beyond just ease of data analysis, another attribute is that it can help free up space and make the database manageable and easier to process. Databases without normalization often need a large amount of memory to store it, with normalization databases can decrease in storage size and increase performance. Databases that are large and contain unnecessary information can slow down the process and quality of data analysis.
What is Data Redundancy?
For a relational database, the user should be able to maintain a single data field, at one location, and make the database’s relational model respond to any changes, to that data field, across the database. Data redundancy occurs when there is unnecessary duplication of data within the database, it not only wastes space but also creates difficult database maintenance issues. While some values are duplicated and redundant, they are not all meaningless, it is still important to use normalization to save storage and avoid errors in updating data.
Without data normalization to mitigate the issue of data redundancy, anomalies like insertion, update, and deletion will occur.
Three types of anomalies:
- Insertion: the inability to add data to the database due to absence of other data.
- Update: a type of data inconsistency that results from data redundancy and a partial update.
- Deletion: loss of data due to the deletion of another type of data.
Common Normal Forms
Normal Forms are rules used in database normalization to reduce redundancy. Here we introduce 4 common normal forms in practical applications.
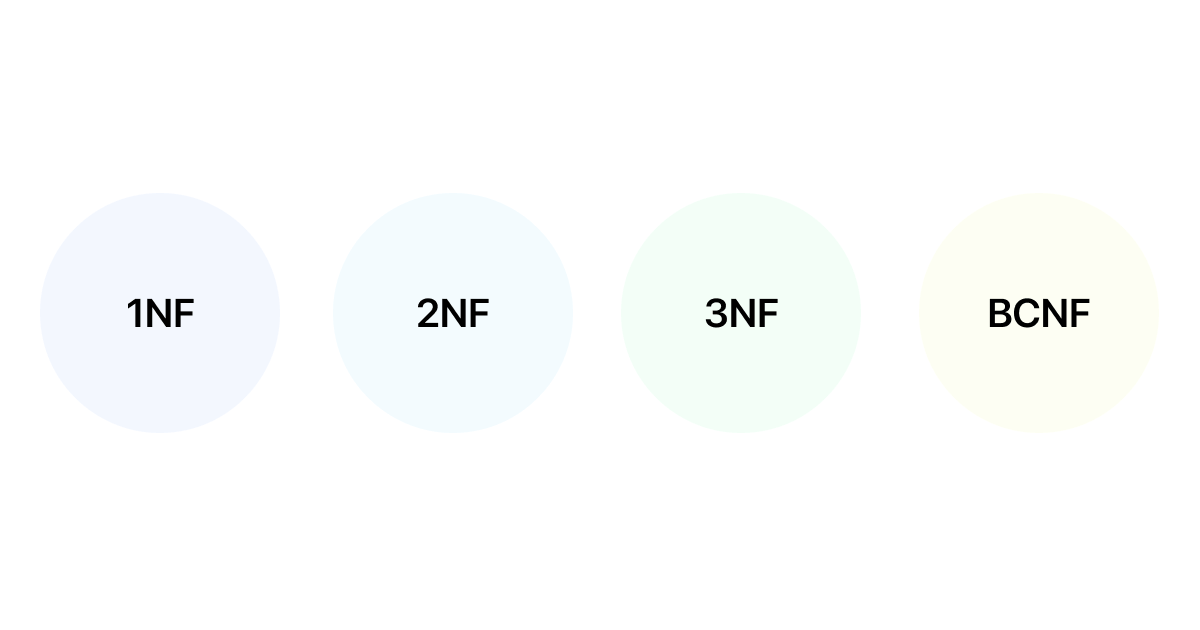
| Normal Form | Rule Description |
|---|---|
| 1NF (First Normal Form) | Each table cell should contain a single value and each record needs to be unique. |
| 2NF (Second Normal Form) | Must be in 1NF and the single column primary key does not depend on any subset of candidate key relations. |
| 3NF (Third Normal Form) | Must be in 2NF and has no transitive functional dependencies. |
| BCNF (Boyce-Codd Normal Form) | Must be in 3NF and for any dependency A → B, A should be a super key. |
Suppose you have an unnormalized table.
| ID | NAME | PHONE |
|---|---|---|
| 214 | Sarah | 7272826385, 2025550160 |
| 226 | Jason | 8574783832 |
| 258 | Mike | 9064738238 |
1NF Example:
| ID | NAME | PHONE |
|---|---|---|
| 214 | Sarah | 7272826385 |
| 214 | Sarah | 2025550160 |
| 226 | Jason | 8574783832 |
| 258 | Mike | 9064738238 |
It states that each table cell cannot hold multiple values. It must hold only single-valued attributes.
2NF Example:
In the given table from the 1NF example, the non-prime attribute PHONE is dependent on ID which is a proper subset of a candidate key. That's why it violates the rule for 2NF.
To convert the given table into 2NF, we decompose it into two tables:
Table 1: User
| ID | NAME |
|---|---|
| 214 | Sarah |
| 226 | Jason |
| 258 | Mike |
Table 2: Phone Number
| ID | NAME |
|---|---|
| 214 | 7272826385 |
| 214 | 2025550160 |
| 226 | 8574783832 |
| 258 | 9064738238 |
3NF Example:
| ID | NAME | ZIP | COUNTRY | CITY |
|---|---|---|---|---|
| 214 | Sarah | 33542 | Canada | Vancouver |
| 226 | Jason | 56729 | US | Denver |
| 258 | Mike | 15893 | Mexico | Tijuana |
In the given table, all attributes except ID are non-prime.
COUNTRY and CITY are dependent on ZIP and ZIP dependent on ID. The non-prime attributes (COUNTRY, CITY) are transitively dependent on the super key(ID). It violates the rule of 3NF.
When we move the COUNTRY and CITY to a new table, with ZIP as a Primary key it will satisfy the 3NF rules:
Table 1: User
| ID | NAME | ZIP |
|---|---|---|
| 214 | Sarah | 33542 |
| 226 | Jason | 56729 |
| 258 | Mike | 15893 |
Table 2: ZIP Code
| ID | COUNTRY | ZIP |
|---|---|---|
| 33542 | Canada | Vancouver |
| 226 | Jason | 56729 |
| 56729 | US | Denver |
| 15893 | Mexico | Tijuana |
BCNF Example:
| ID | NAME | ZIP | COUNTRY | CITY |
|---|---|---|---|---|
| 214 | Sarah | 33542 | Canada | Vancouver |
| 226 | Jason | 56729 | US | Denver |
| 258 | Mike | 15893 | Mexico | Tijuana |
In the above table functional dependencies are as follows:
ID → NAME
ZIP → {COUNTRY, CITY}
The table is not in BCNF because neither EMP_DEPT nor EMP_ID alone are keys. To convert the given table into BCNF, we decompose it into three tables:
Table 1: User
| ID | NAME |
|---|---|
| 214 | Sarah |
| 226 | Jason |
| 258 | Mike |
Table 2: ZIP Code
| ZIP | COUNTRY | CITY |
|---|---|---|
| 33542 | Canada | Vancouver |
| 56729 | US | Denver |
| 15893 | Mexico | Tijuana |
Table 3: User Address
| ID | ZIP |
|---|---|
| 214 | 33542 |
| 226 | 56729 |
| 258 | 15893 |
How do we use data normalization?
Data normalization is a technique to design and manage the database system. We can also apply the principles to transform or clean our dataset. Many ETL (Extract, Transform, Load) tools provide users the ability to normalize data. If data is stored in JSON or NoSQL databases, it’s not easy to analyze it. Since data is not stored in a structured and tabular format, you cannot differentiate dimensions and metrics. Acho’s actions are used for transforming data into a ready-to-use format. Within Acho, there are actions within the “Data Cleansing” function, one of which is called “Flatten”. Flatten is mainly used for dealing with JSON or arrays. JSON generally puts another table into a column, whereas an array puts a list of values within a column. The process to flatten JSON and array is one way to normalize the database.
Extracting values from JSON:
Step 1: Go to the table that includes JSON objects and navigate to Data Cleaning > Flatten.
Step 2: Choose a column and select Flatten JSON. (All JSON columns are presented in a String data type)
Step 3: Type the keys that you want to extract values from. Here you can type several keys, and you can enter space to separate each key. (Remember to click Enter when you finish a keyword.)
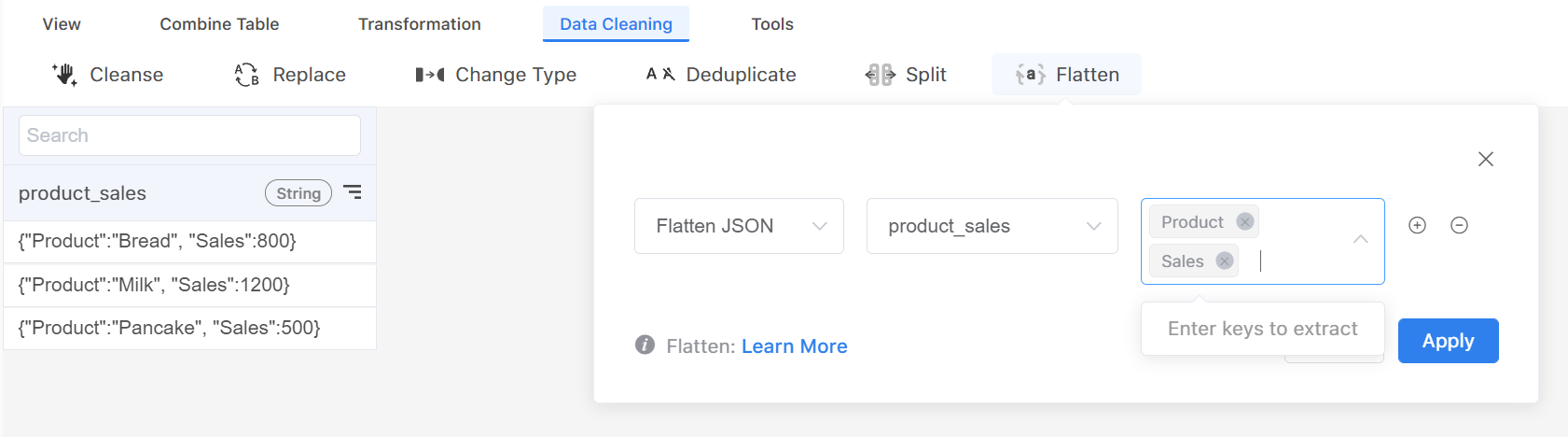
Step 4: The system will extract a specific key's value from each row and put these values in another column. The new column will have a prefix of the original JSON column. (You can use Rename action to change the column name)

Flattening values from an array:
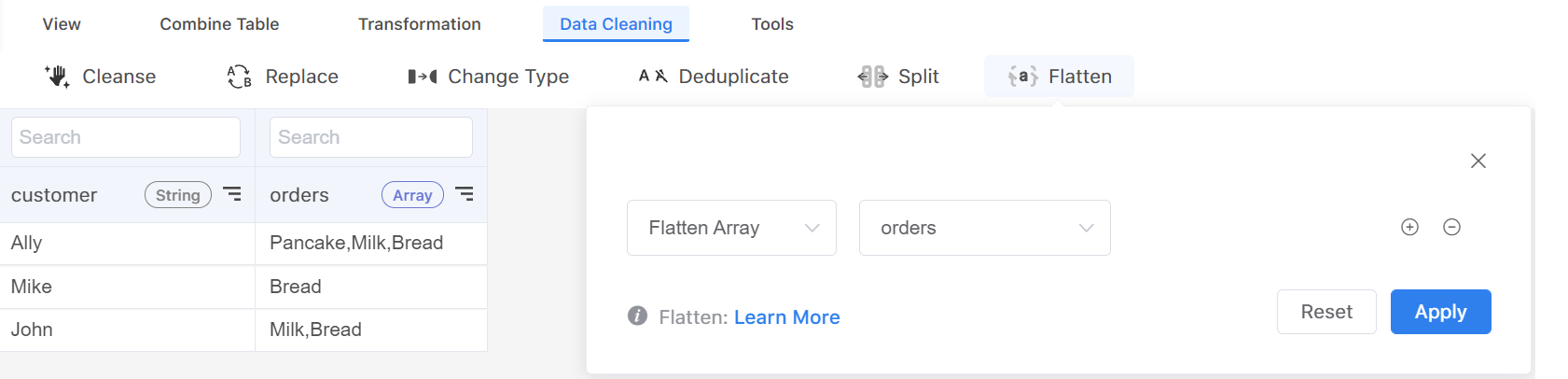
Step 1: Go to the table that includes JSON objects and navigate to Data Cleaning > Flatten.
Step 2: Choose a column and select Flatten Array. Note that you can only choose columns in an Array data type.
Step 3: The system will separate each element into different rows and put these values in another column.
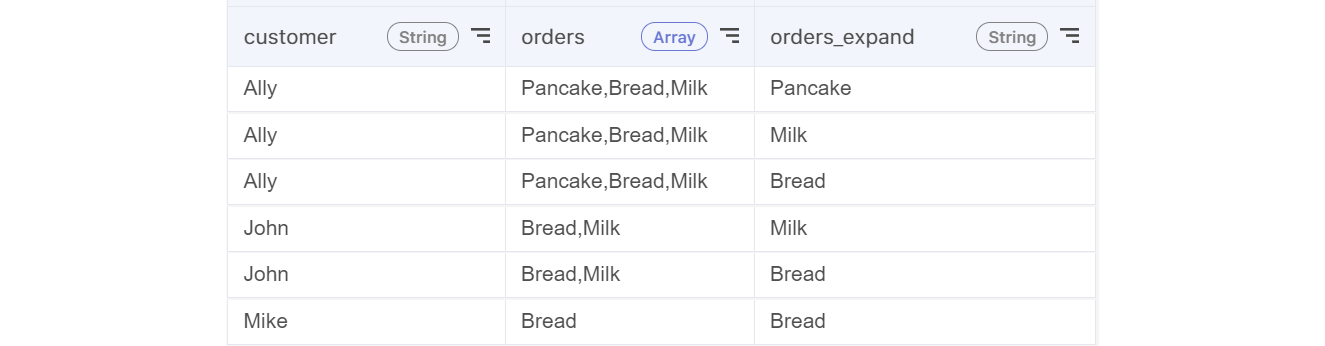
Step 4: Each element in an array will be separated into different rows as shown below. The new column will have a prefix of the original Array column. (You can use Rename action to change the column name)
Being able to analyze big data is crucial to an organization’s success. Imagine having a disorganized dataset, there is a potential of missing key information and data trends that could have helped with an organization’s growth. With the knowledge of database normalization, it makes organizing and cleaning data easier and more efficient.